END-TO-END SOLUTION
Peptide Discovery
The challenges of Peptide Discovery
The abundance vs. affinity trap
Traditional screening samples a tiny fraction of a library, causing teams to miss rare, high-affinity peptides. Even with NGS, relying on static frequency often mistakes fast-growing passenger clones for actual target binders.
Late-stage developability failures
Strong binders frequently fail late in development due to unseen physicochemical weaknesses. Unflagged sequence liabilities cause costly downstream aggregation, oxidation, and proteolytic degradation.
Fragmented toolchains
Discovery teams rely on fragmented toolchains—command-line aligners, spreadsheets, and isolated scripts. These disconnected silos compromise data provenance, making reproducible analysis nearly impossible.
Lack of motif diversity
Selecting abundant clones often yields nearly identical sequences. If that single motif family fails wet-lab testing, the entire campaign fails. Sifting through millions of reads to find structurally diverse candidates is notoriously difficult.
From raw reads
to confident leads
Replace disconnected scripts with a single, governed environment. Platforma seamlessly processes millions of NGS reads across selection rounds to track enrichment, flag liabilities early, and cluster distinct peptides. Move from raw data to a diverse, high-confidence panel of candidates.
The peptides analysis suite


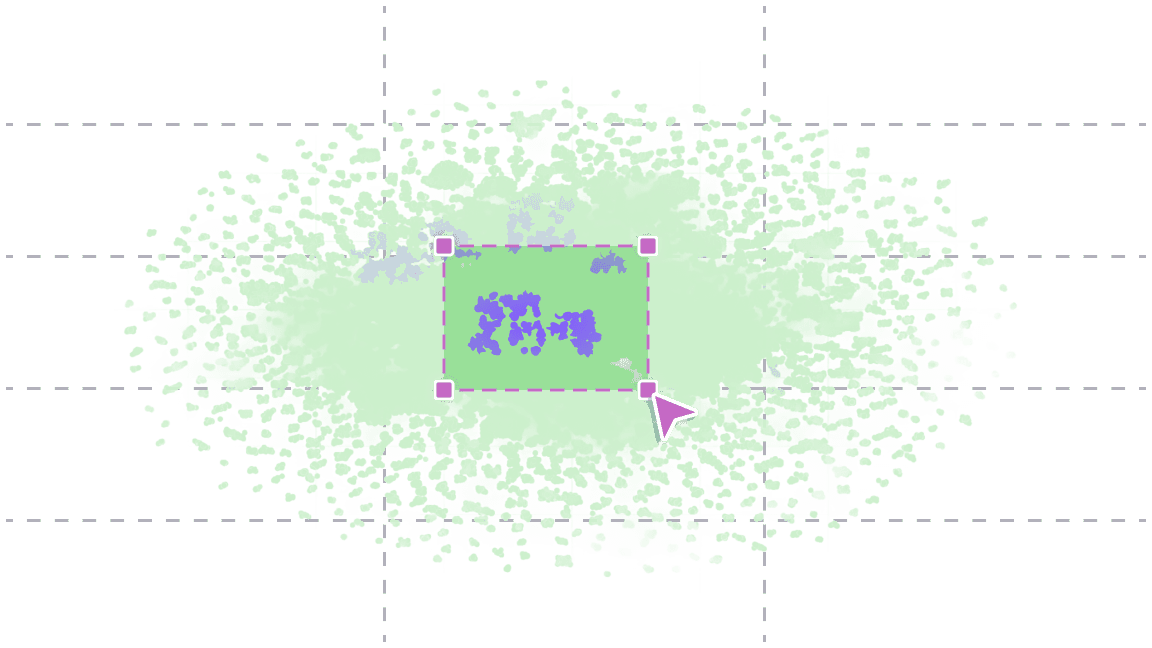
Peptide space
Visualize the entire discovery campaign. Map millions of peptides in a unified UMAP space to compare conditions, identify enriched clusters, and spot diversity blindspots instantly.
Peptide clustering
Group sequences into distinct functional families. Guarantee motif diversity in your lead panel by avoiding redundant peptides.

Enrichment analysis
Track selection dynamics with precision. Calculate fold-change across successive panning rounds to confidently differentiate high-affinity target binders from fast-growing passenger clones.

Liabilities
Flag developability risks before costly wet-lab validation. Automatically annotate critical liabilities directly on the sequence.

Lead prioritization
Triangulate your best hits. Integrate enrichment scores, liability flags, clustering data into a unified workspace for confident decision-making.

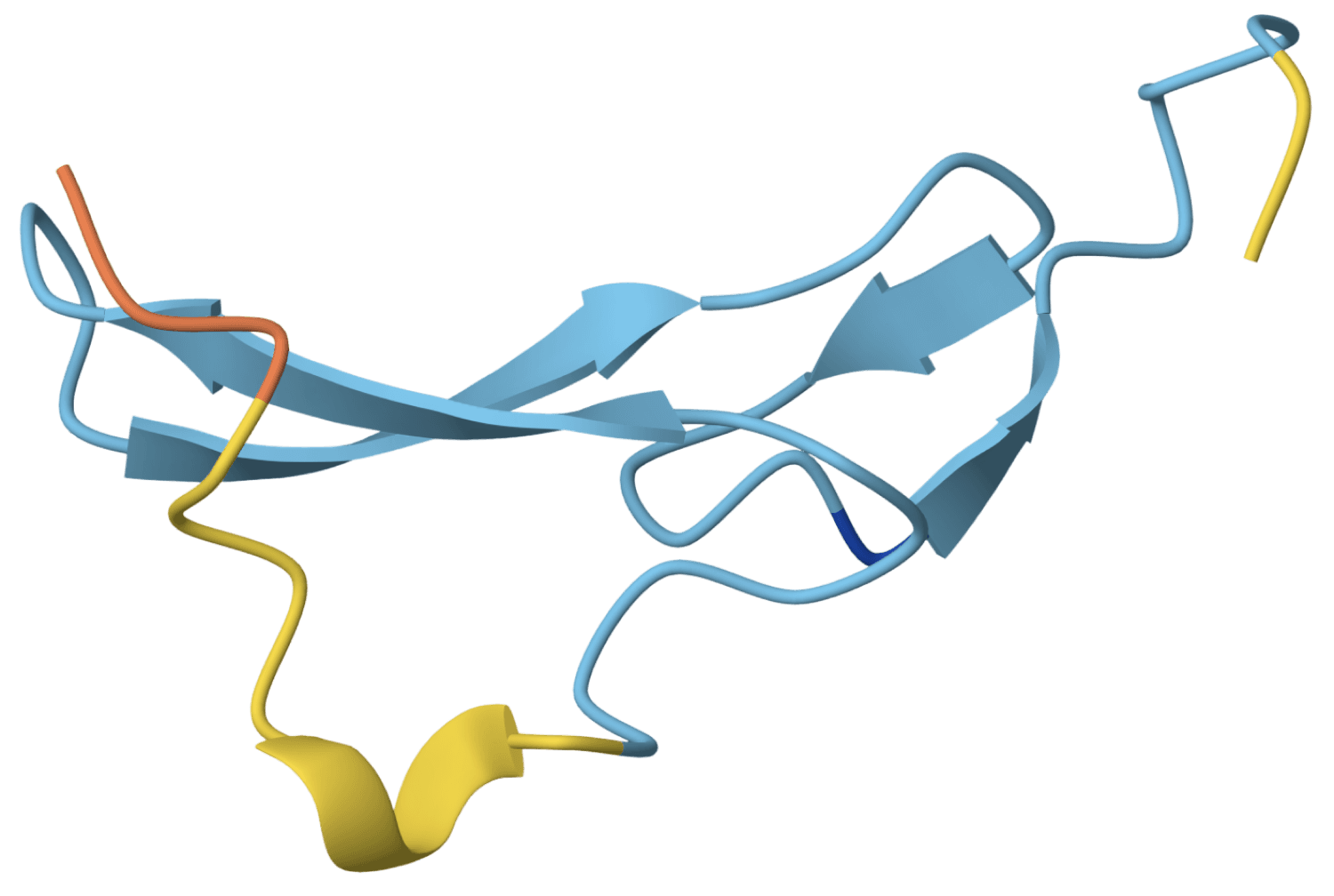
Structure modeling
Move beyond sequence-only analysis. Generate high-quality 3D peptide models to assess binding surfaces and support structure-informed downstream validation.
Reproducible workflows
Standardize your discovery pipelines. Deploy white-box, auditable workflows that ensure data provenance and scalability.

End-to-end workflow

Data input & annotation
NGS of linear, cyclic, bicyclic peptide libraries
Multiple enrichment arms, negative controls
Powered by the industry-standard MiXCR engine
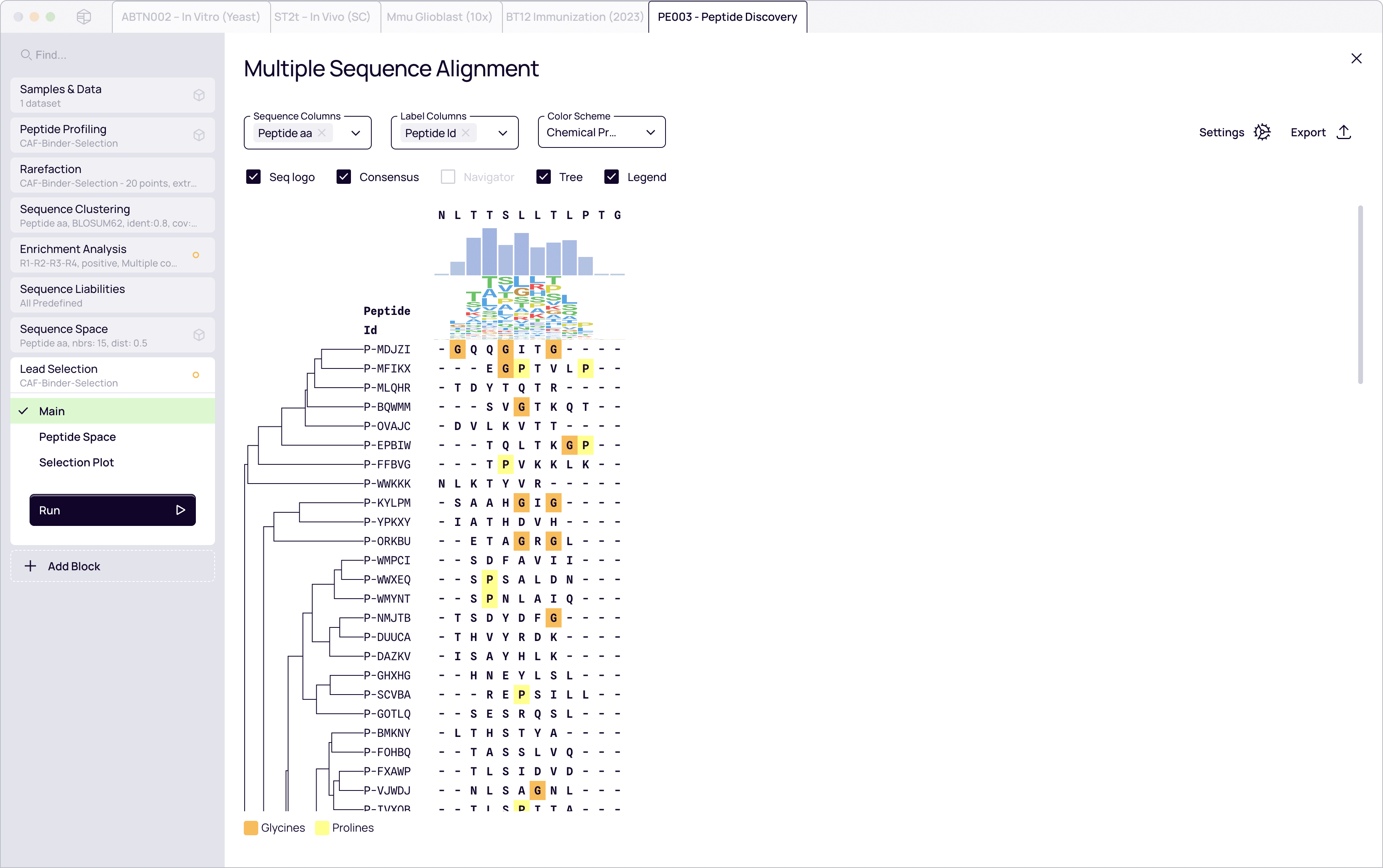
Peptide clustering
Versatile clustering to group distinct families
Group by variable region or full peptide sequences
Powered by the industry-standard MMSeqs2 engine
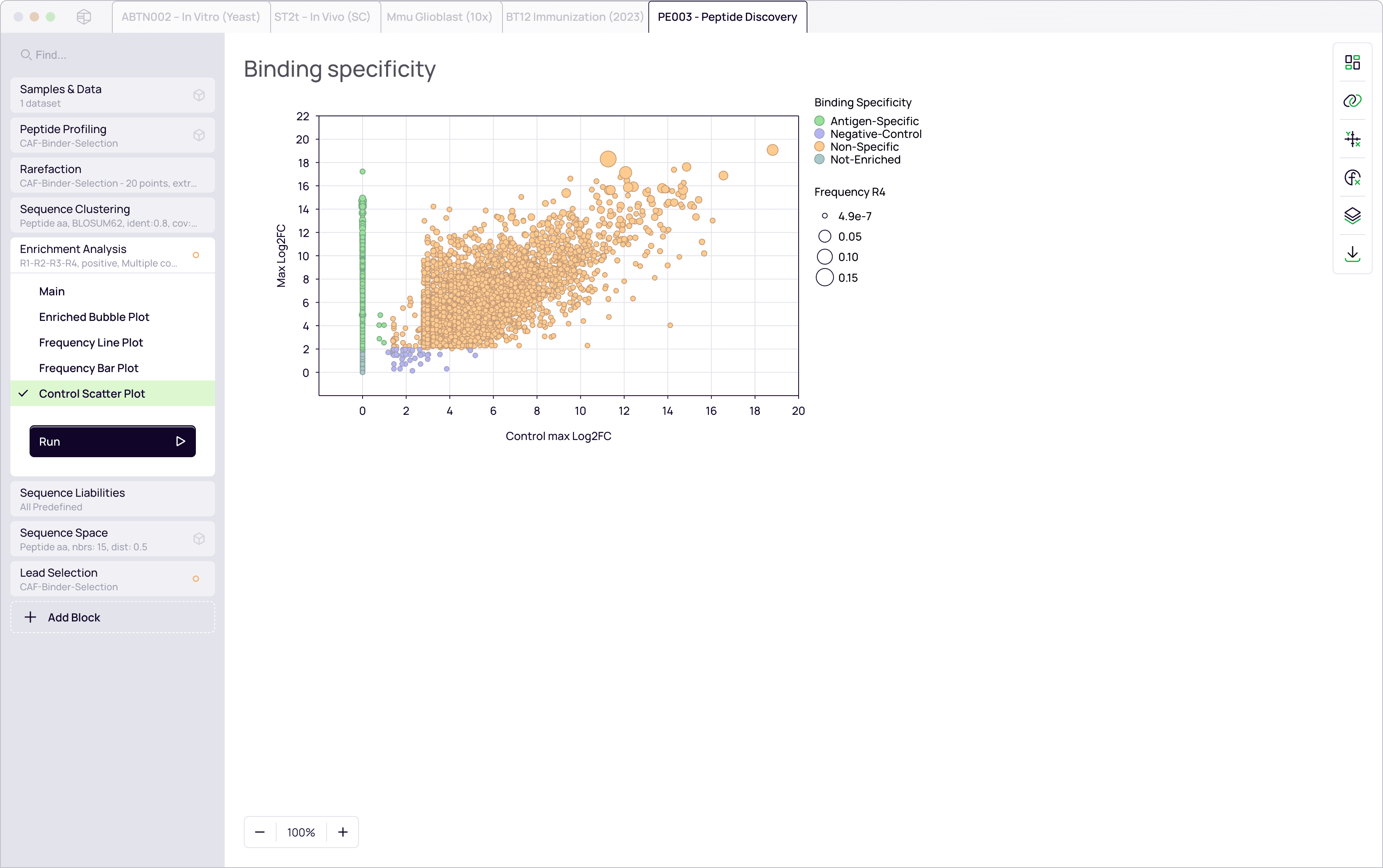
Enrichment analysis
Track frequency changes across rounds
Identify binders and rescuers versus parasites
Include negative control to track antigen specific peptides
De-risking
Configure liability flags by sequence position
Assess structural liabilities
Integrate functional assay data
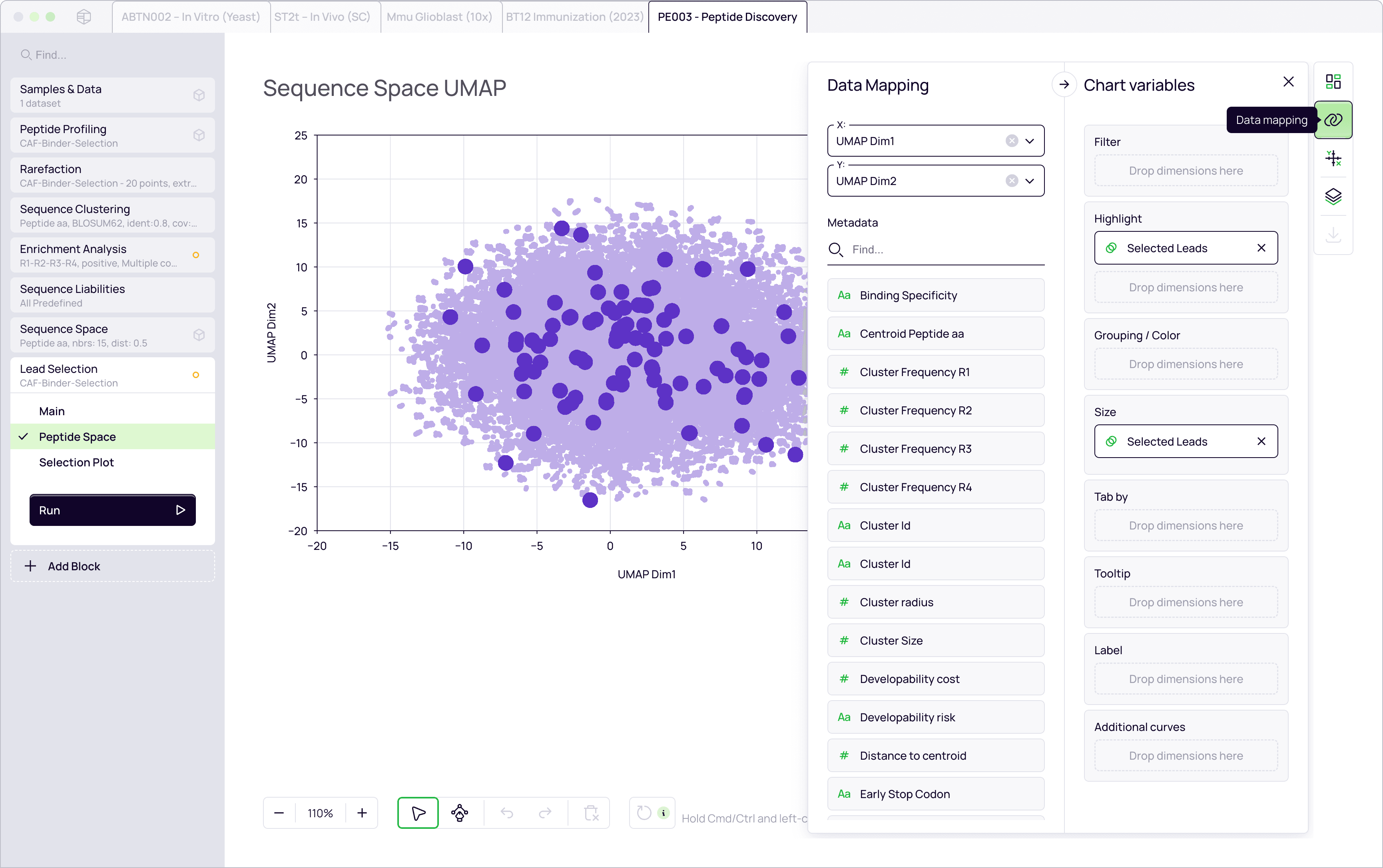
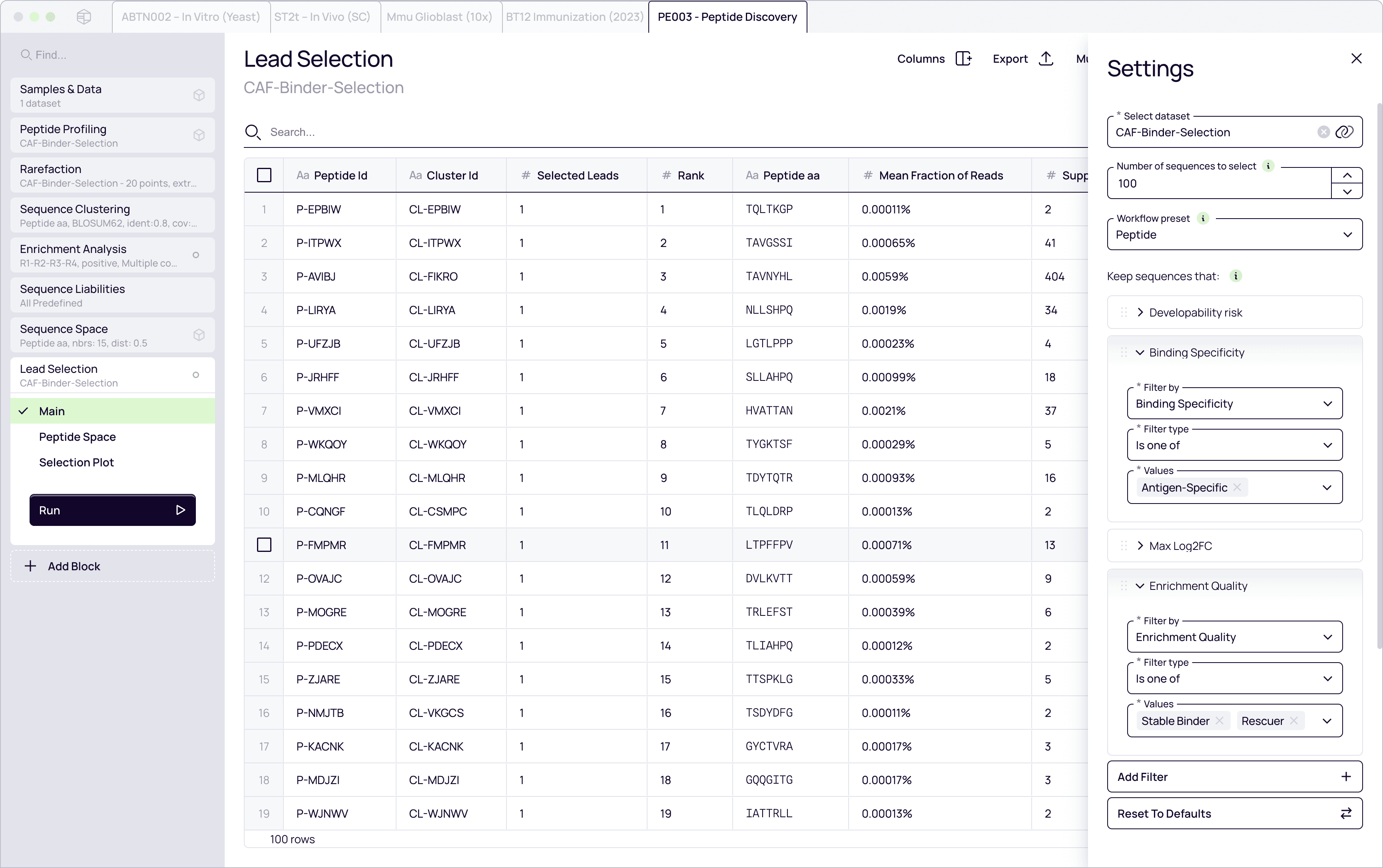
Candidate prioritization
Integrate enrichment scores, liability flags, clustering data
Visualize entire repertoire on interactive map
Triangulate best hits